VIDEO: Project Gameface pokreće se na Androidu
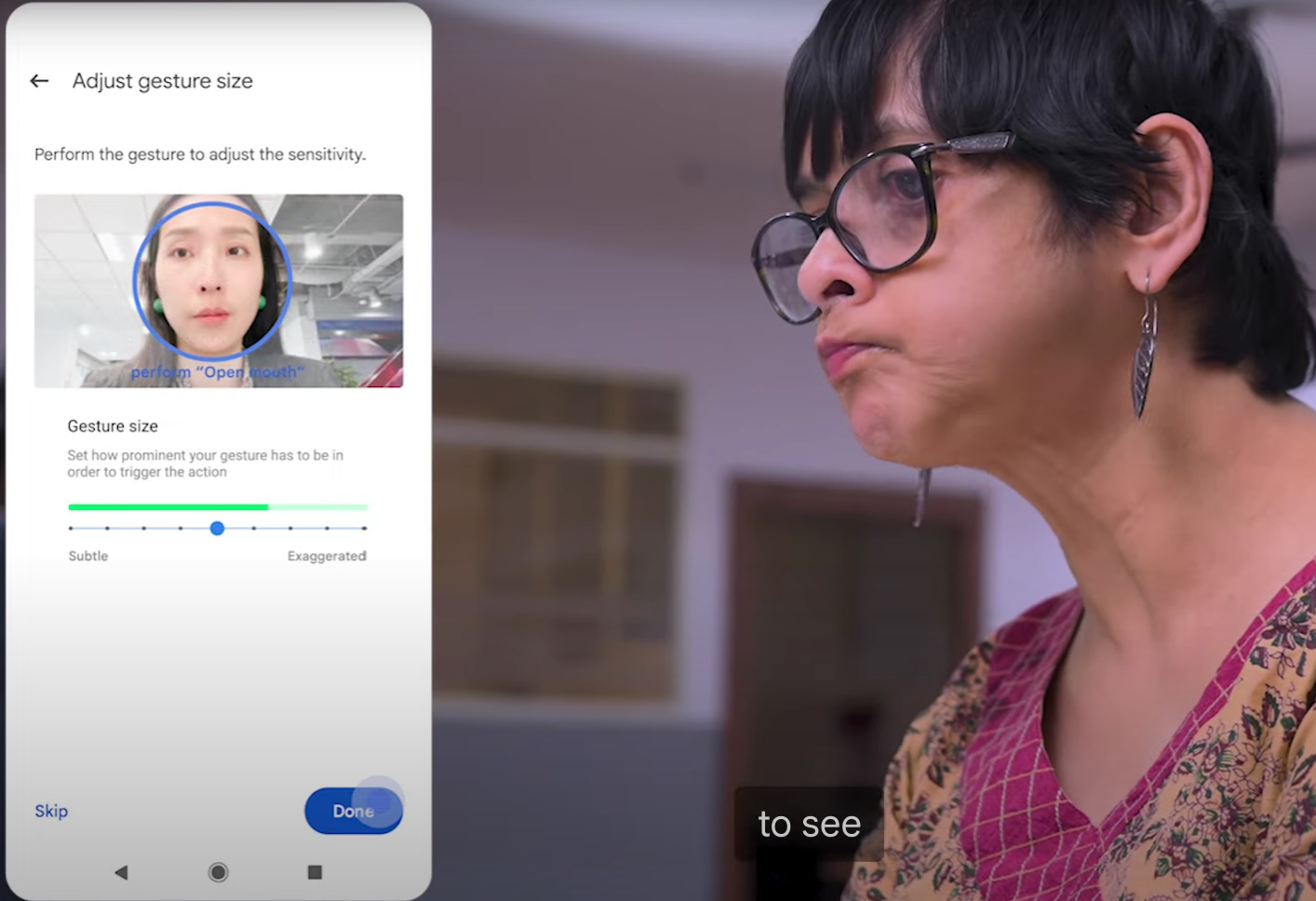
Google je na prošlogodišnjoj I/O konferenciji pokrenuo Project Gameface , 'miša' za igranje bez upotrebe ruku otvorenog koda koji ljudima omogućuje upravljanje pokazivačem računala pomoću pokreta glave i gestikulacija lica. Ljudi mogu podići obrve kako bi kliknuli i povukli ili otvoriti usta kako bi pomaknuli kursor, čineći igranje pristupačnijim.
Na ovogodišnjoj I/O konferenciji Google je rekao da je otvorio "više koda" za Project Gameface, omogućujući razvojnim programerima izradu Android aplikacija koje mogu koristiti tehnologiju.
Projekt je inspiriran pričom streamera videoigara...
- Objavljeno u POP TECH