Automatizirani sustav poziva na suradnju s AI-jem
- Objavljeno u Znanost
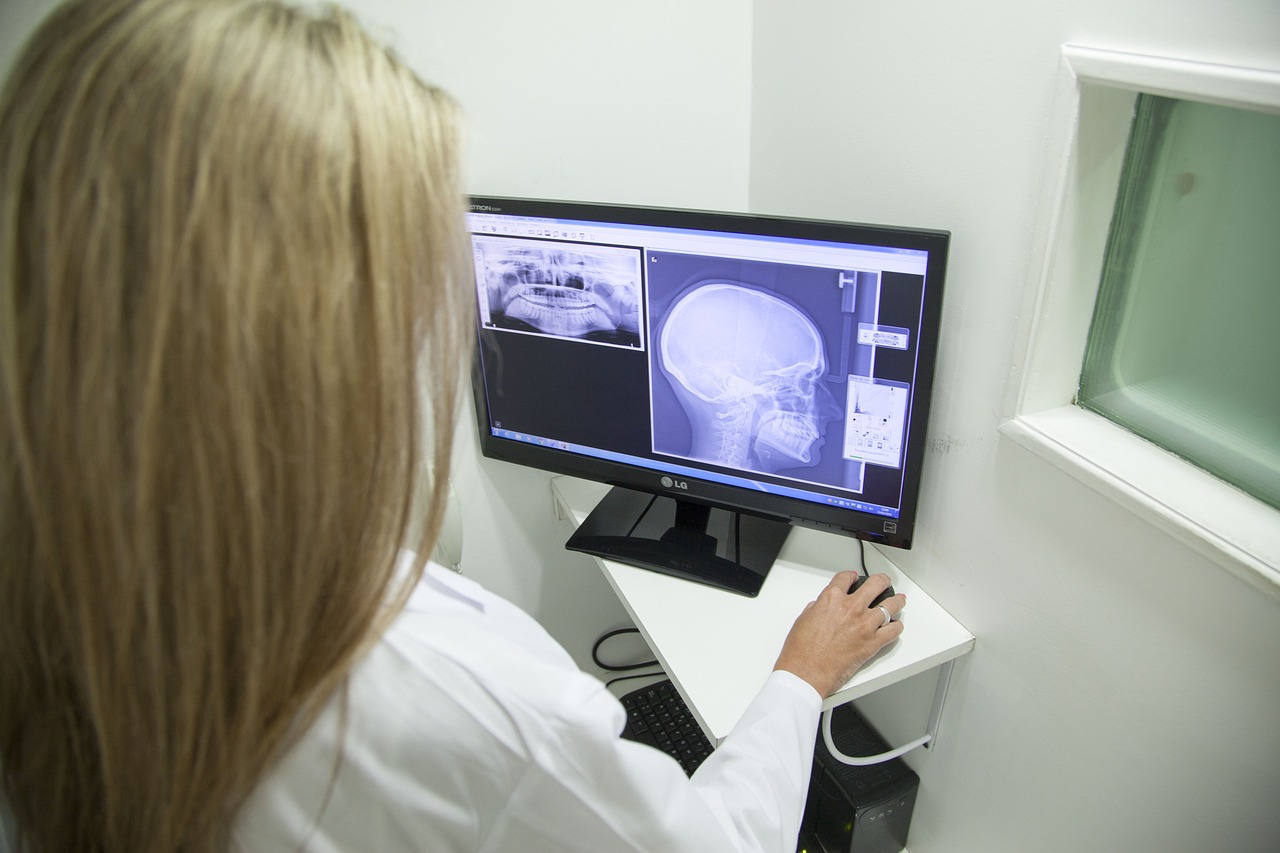
Modeli umjetne inteligencije koji odabiru uzorke na slikama često to mogu učiniti bolje od ljudskih očiju, ali ne uvijek. Ako radiolog koristi AI model kako bi mogao odrediti pokazuju li pacijentove rendgenske snimke znakove upale pluća, kada bi trebao vjerovati savjetu modela, a kada bi ga trebao zanemariti?
Prilagođeni proces uključivanja mogao bi pomoći ovom radiologu da odgovori na to pitanje, prema istraživačima s MIT-a i MIT-IBM Watson AI Laba, koji su osmislili sustav koji uči korisnika kada treba surađivati s AI pomoćnikom.
U ovom slučaju, metoda obuke može pronaći situacije u kojima radiolog vjeruje savjetu modela, osim što ne bi trebao ako model nije u pravu. Sustav automatski uči pravila kako bi čovjek trebao surađivati s umjetnom inteligencijom i opisuje ih prirodnim jezikom.
Tijekom uključivanja, radiolog vježba suradnju s umjetnom inteligencijom koristeći vježbe obuke temeljene na ovim pravilima, primajući povratne informacije o svojoj izvedbi i izvedbi umjetne inteligencije.
Istraživači su otkrili da je ovaj postupak uključivanja doveo do oko 5 posto poboljšanja u točnosti kada su ljudi i umjetna inteligencija surađivali na zadatku predviđanja slike. Njihovi rezultati također pokazuju da je samo govorenje korisniku kada treba vjerovati AI-u, bez obuke, dovelo do lošijih performansi.
Važno je reći da je sustav potpuno automatiziran, tako da uči kreirati proces uključivanja na temelju podataka od čovjeka i umjetne inteligencije koji obavljaju određeni zadatak. Također se može prilagoditi različitim zadacima, tako da se može povećati i koristiti u mnogim situacijama u kojima ljudi i AI modeli rade zajedno, kao što je moderiranje sadržaja društvenih medija, pisanje i programiranje.
Prvi korak sustava je prikupljanje podataka o ljudima i umjetnoj inteligenciji koji obavljaju ovaj zadatak.
Sustav ugrađuje te podatkovne točke u latentni prostor, koji predstavlja prikaz podataka u kojem su slične podatkovne točke bliže jedna drugoj. Koristi se algoritmom za otkrivanje područja ovog prostora u kojima čovjek neispravno surađuje s umjetnom inteligencijom. Ove regije bilježe slučajeve u kojima je čovjek vjerovao predviđanju umjetne inteligencije, ali je predviđanje bilo pogrešno, i obrnuto.
Nakon otkrivanja regija, drugi algoritam koristi veliki jezični model za opisivanje svake regije u pravilu, koristeći prirodni jezik. Algoritam iterativno fino podešava to pravilo pronalaženjem kontrastnih primjera.
Ova se pravila koriste za izradu vježbi treninga. Onboarding sustav pokazuje primjer čovjeku, kao i AI-jevo predviđanje, te pita korisnika pokazuje li slika određeni objekt. Korisnik može odgovoriti s da, ne, ili koristiti predviđanje umjetne inteligencije.
Ako čovjek griješi, prikazuje mu se točan odgovor i statistika izvedbe za čovjeka i umjetnu inteligenciju na ovim instancama zadatka. Sustav to radi za svaku regiju, a na kraju procesa treninga ponavlja vježbe koje je čovjek pogriješio.
Istraživači su testirali ovaj sustav s korisnicima na dva zadatka, otkrivanju semafora na mutnim slikama i odgovaranju na pitanja s višestrukim izborom iz mnogih domena poput biologije, filozofije i informatike.
Prvo su korisnicima pokazali karticu s informacijama o modelu umjetne inteligencije, kako je obučen i raščlambom njegove izvedbe u širokim kategorijama. Korisnici su podijeljeni u pet skupina: nekima je samo pokazana kartica, neki su prošli kroz proceduru uključivanja istraživača, neki su prošli kroz proceduru uključivanja na početnu razinu, neki su prošli proceduru uključivanja istraživača i dobili su preporuke kada bi trebali, a kada ne bi trebali vjerujte umjetnoj inteligenciji, a drugi su dobili samo preporuke.
Samo je postupak uključivanja istraživača bez preporuka značajno poboljšao točnost korisnika, pojačavši njihovu izvedbu na zadatku predviđanja semafora za oko 5 posto bez usporavanja. Međutim, uključivanje nije bilo tako učinkovito za zadatak odgovaranja na pitanja. Istraživači vjeruju da je to zato što je model umjetne inteligencije, ChatGPT, uz svaki odgovor dao objašnjenja koja pokazuju treba li mu vjerovati.
No davanje preporuka bez uključivanja imalo je suprotan učinak, korisnici ne samo da su imali lošije rezultate, već im je trebalo više vremena za predviđanje.
U budućnosti istraživači žele provesti veća istraživanja kako bi procijenili kratkoročne i dugoročne učinke onboardinga. Također žele iskoristiti neoznačene podatke za proces uključivanja i pronaći metode za učinkovito smanjenje broja regija bez izostavljanja važnih primjera.
Znanstveni rad istraživača MIT-a koji će biti prezentiran na NeurIPS 2023 Konferenciji o sustavima obrade neuronskih informacija možete pronaći na ovoj poveznici.