AI razumije govor koji se ne izgovara naglas
- Objavljeno u Znanost
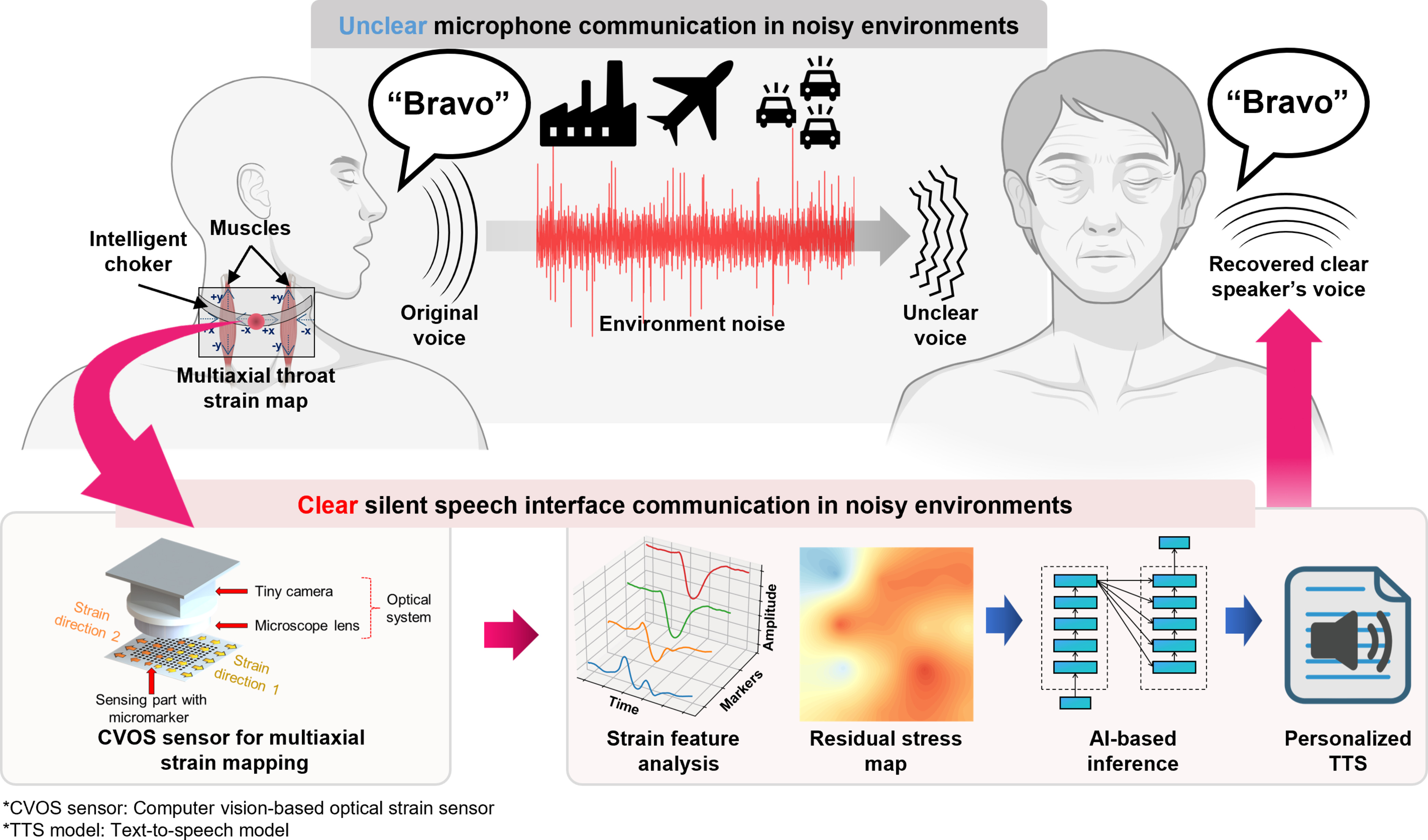
Sučelja za tihi govor (SSI) nude održivu alternativu tradicionalnim mikrofonima u snimanju jasnog zvuka u bučnim okruženjima.
Istraživači s južnokorejskog Sveučilišta znanosti i tehnologije Pohang (POSTECH) razvili su rekonceptualizirani SSI koji reproducira glas praćenjem kontinuiranih višeosnih mapa naprezanja izazvanih pokretima mišića grla.
Sustav integrira senzor optičkog naprezanja temeljen na računalnom vidu (CVOS) s rekonstrukcijom glasa temeljenom na dubokom učenju, omogućujući jasnu komunikaciju u ekstremnim uvjetima buke.
CVOS senzor, koji se sastoji od mekane silikonske podloge s mikromarkerima i sićušne kamere, postiže visokoosjetljivo otkrivanje markera i bilježi složene obrasce naprezanja s većom skalabilnošću i pouzdanošću u usporedbi s konvencionalnim nosivim senzorima.
Cjevovod inferencije SSI-ja temeljenog na CVOS-u uključuje automatiziranu kalibraciju osnovne linije temeljenu na fizici i vremensku pažnju prilagođenu sadržaju, što omogućuje robusnu analizu snimljenih obrazaca naprezanja. Na temelju rezultata inferencije, personalizirani model pretvaranja teksta u govor naknadno rekonstruira glas govornika.
Ove algoritamske značajke osiguravaju robusnost u dinamičkim uvjetima korištenjem adaptivne obrade signala u stvarnom vremenu koja kompenzira inter- i intrasubjektnu anatomsku varijabilnost.
Komunikacija temeljena na abecedi postiže se sinergijom između optimiziranih algoritama i dizajna sučelja. Performanse SSI-ja temeljenog na CVOS-u validirane su u stvarnim scenarijima s puno buke, što potvrđuje njegovu praktičnu primjenjivost.
Ogrlica za vrat koja "čita" pokrete izrađena je od neoprenske tkanine debljine 1,5 mm, elastične trake debljine 2 mm, čičak traka, kopči s otvorenim zatvaračem i kopči. CVOS senzor pričvršćen je na traku neoprenske tkanine širine 20 mm. Kombinacija elastične trake, čička i kopči s otvorenim zatvaračem omogućuje podešavanje duljine ogrlice kako bi odgovarala veličini tijela korisnika.
Glavni dio sustava je AI algoritam za analizu višeosnih naprezanja u stvarnom vremenu CVOS senzora. Slika je binarizirana Otsuovom metodom, učinkovito razlikujući mikromarkere od Ecoflex podloge dodjeljivanjem različitih boja. Konačno, okviri za ograničavanje mikromarkera izdvojeni su iz binarizirane slike. Okviri koji su bili premali ili preveliki isključeni su iz ekstrakcije.
Informacije o riječi dobivene od klijenta (korisnika koji nosi SSI uređaj) prenose se na poslužitelj, gdje se odgovarajuća riječ dohvaća s unaprijed definiranog popisa, sintetizira u zvuk i isporučuje korisniku putem audio streama. Implementacija TTS-a temelji se na projektu otvorenog koda, piper-tts, s TTS modelom pretvorenim u format Open Neural Network Exchange postavljenim na poslužitelju.
Budući rad usredotočit će se na unapređenje predloženog SSI-ja temeljenog na CVOS-u od temeljne demonstracije izvedivosti prema potpuno skalabilnoj platformi za komunikaciju tihim govorom. Dok je ova studija dala prioritet uspostavljanju pouzdanog okvira za očitavanje i modeliranje u kontroliranim uvjetima, naknadna istraživanja proširit će veličinu i raznolikost skupa podataka uključivanjem veće grupe sudionika, višesesijskih snimaka i širih leksičkih skupova, čime će se omogućiti rigorozna validacija modela i podržati prijelaz na veliki vokabular i na kraju kontinuirano dekodiranje tihog govora.
Znanstveni rad objavljen u časopisu Cyborg Bionic Systems, možete pronaći na ovoj poveznici.