Seksistička i rasistička podatkovna baza trenirala AI
- Objavljeno u Svijet
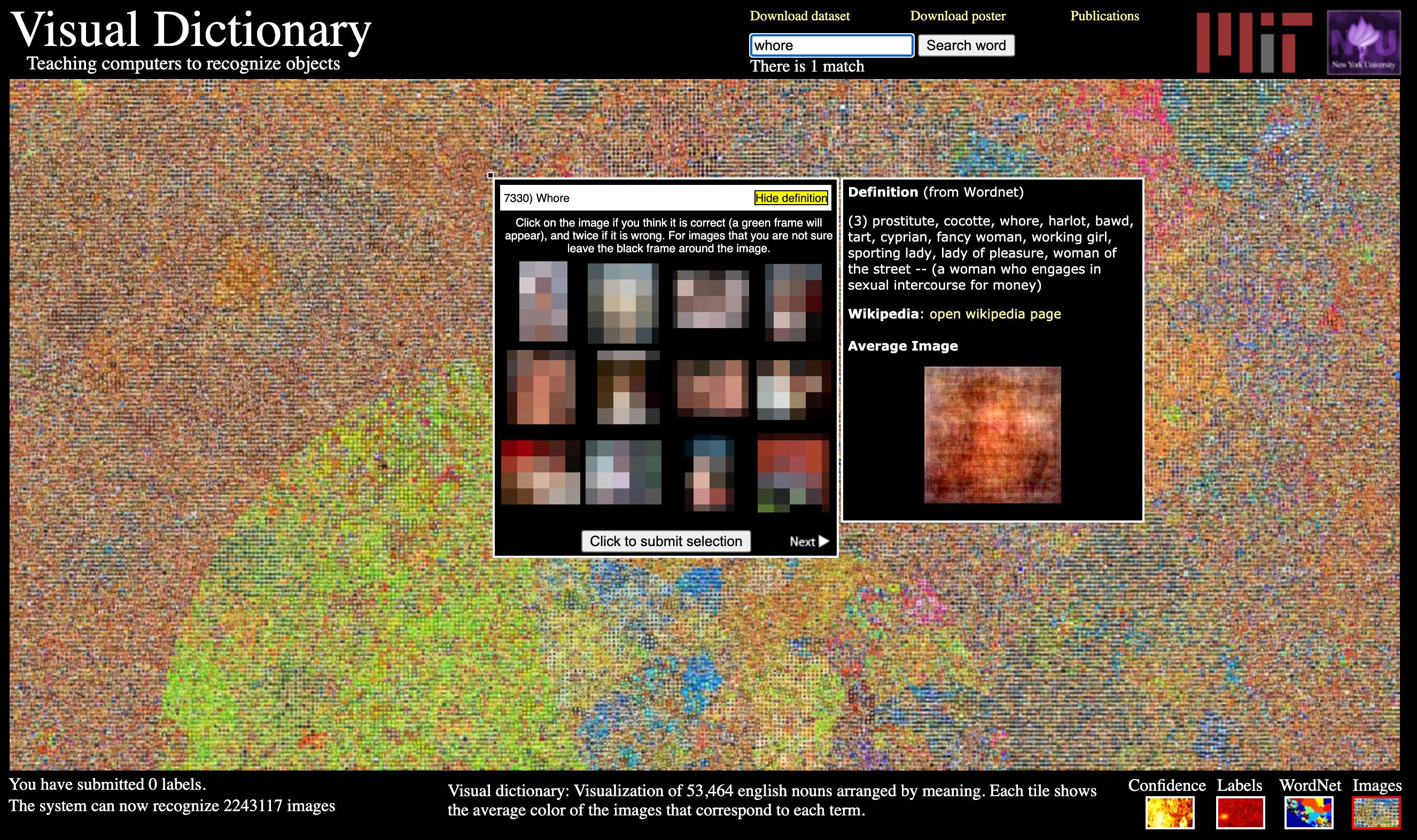
Jedno od najvećih tehnoloških sveučilišta i istraživačkih institucija na svijetu MIT, povuklo je s interneta veliku podatkovnu bazu koja se koristila za uvježbavanje neuralnih mreža i algoritama umjetne inteligencije za prepoznavanje objekata, ljudi i životinja.
Podatkovna baza koju je razvio MIT, koristila se za učenje modela strojnog učenja u automatskoj identifikaciji ljudi i objekata temeljem fotografija. Na primjer, ukoliko AI-u pokažete sliku parka, on vam može u djeliću sekunde reći mnoštvo informacija o djeci, odraslima, kućnim ljubimcima, travi i drveću koje se nalazi u sceni. No zahvaljujući MIT-evom automatskom unosu podataka koji očito nitko nije kontrolirao, AI može žene nazvati kurvama ili kujama, a crnce ili azijate pogrdnim rasističkim nazivima. Pored toga podatkovna baza je sadržavala i slike ženskih genitalija koja je imenovala prostačkim kolokvijalnim nazivima.
Ta podatkovna baza koja je kreirana 2008. godine sadržavala je oko 80 milijuna sličica s namjenom korištenja u stvaranju naprednih tehnika prepoznavanja objekata. Uz svaku od tih slika nalazio se tekst kojim se opisuje što se nalazi na njoj, a ti su se podaci mogli ubacivati u neuralne mreže kako bi ih se učilo u povezivanju uzoraka iz slika s tekstualnim opisima.
Baza je nosila ime Tiny Images jer su slike u biblioteci bile vrlo male kako bi ih algoritmi računalnog vida s kraja 2000-ih godina mogli procesirati.
Problem s neprimjerenim opisima su otkrili Vinay Prabhu, znanstvenik u privatnoj tvrtki iz Silicijske doline UnifyID i Abeba Birhane, doktorandica na sveučilištu University College Dublin iz Irske koji su u bazi otkrili na tisuće slika s rasističkim opisima Azijata i crnaca te prostačkim izrazima za definicije žena. Njihov detaljni izvještaj napisan u obliku znanstvenog rada možete pronaći na ovoj poveznici.
Među tim opisima su između ostaloga otkrili slike žena u bikinijima, pa čak i žena s djecom u rukama koje su nazvane kurvama.
Profesor računalnih znanosti u MIT CSAIL-u Antonio Torralba kaže da njegov laboratorij nije bio svjestan tih uvredljivih opisa i slika te se ispričava svima što ih nitko na MIT-u nije ručno pregledavao. "Čim smo na to upozoreni stavili smo podatkovnu bazu offline kako bi se uvredljive slike i opisi mogli ukloniti", navodi Torralba u službenoj isprici na ovoj poveznici.
Obzirom da se radi o 80 milijuna sličica veličine od samo 32 x 32 piksela, teško je vjerovati da će ih netko sve ručno pregledati i potom ukloniti neprimjerene, a postoji i velika mogućnost da će štetu biti teško popraviti, jer su mnogi algoritmi koji se aktivno koriste u brojnim AI sustavima već prošli trening na spornoj podatkovnoj bazi.
Torralba kaže da su mnoge slike jednostavno direktno kopirane s interneta, pa ističe primjer s 53.464opatica čije slike su direktno povučene s WordNeta i potom automatski povezane s definicijama iz podatkovne baze engleskih riječi Sveučilišta Princeton.
Birhane i Prabhu se čude što nitko nije kontrolirao automatsko povlačenje definicija iz velikih online rječnika koji sadrže sve kolokvijalizme koji se koriste u govoru, obzirom da se ovdje nije radilo o jezičnoj znanosti, već o umjetnoj inteligenciji koju stvaramo da bude pametna i korisna, ali i da poštuje civilizacijska načela koja želimo u nju ugraditi.